首页>博客>行业科普>GraphRAG:用知识图谱与生成式AI开创关系感知的智能新时代
GraphRAG:用知识图谱与生成式AI开创关系感知的智能新时代

随着大语言模型(LLM)的广泛应用,如何让模型突破训练数据的限制、减少“幻觉”并回答复杂关系问题,成为业界关注焦点。本文将系统介绍最新的GraphRAG(基于图的检索增强生成)技术,从原理、架构到应用与未来挑战,全面解析知识图谱与大模型如何共创“可检索、可推理、可解释”的AI系统。读完全文,您将系统掌握GraphRAG与RAG、向量数据库、结构化查询等主流技术方案的异同,了解其企业实践路径和技术栈选择。
1.什么是RAG(检索增强生成)?
背景
大语言模型(LLM)凭借强大的自然语言理解生成能力,已在众多领域展现出非凡潜力。但模型固有的“知识冻结”“幻觉生成”及领域知识深度不足等问题,限制了其商业与科研应用场景。
RAG定义
RAG本质是在生成前动态检索外部知识库,模型不仅依赖参数化记忆,更能实时查找上下文信息,因此大幅提升了准确性、时效性与可靠性。传统RAG一般分为两个核心组件:
Retriever 检索器: 将用户问题与知识库中文本分块进行语义向量匹配,找出最相关的内容段;
Generator 生成器: 通常为LLM,结合检索到的上下文和原始问题进行答案生成。
RAG优势:
提升准确率、可查性和透明度
零/低成本支持知识库“热更新”
支持个性化和领域定制
2.传统RAG的局限
虽然通过语义相似性检索提升了可用性,但传统RAG多以“非结构化文本块”作为知识单元,难以支持高级推理与复杂关系检索。主要难题包括:
语义瓶颈(Semantic Bottleneck)
基于向量的语义检索擅长主题相关文档,但对“特定实体/事件之间的关系”理解薄弱。例如:“A公司收购B对C有什么市场影响?”——很难通过独立文本块准确串联三个实体间的因果关系。
忽视显式关系
文本分块会打断实体之间的明晰联系,无法优先检索多个事件或复杂流程间的交互路径。
多跳推理挑战
复杂问题往往需要“多跳推理”(Multi-hop Reasoning)。传统RAG尽管能检索主体片段,但难以显式组合推理链路,对LLM推理负担极大,容易信息噪声或不完整。
关系型数据“上下文断裂”
如供应链、法律、生命科学医学等本质是图结构领域,信息之间的联系比孤立事实更重要。若扁平成文本分块,模型难以复原实体间的网络。
3.图数据库与知识图谱:关系表达的“利器”
图数据库简介
图数据库是一种通过“节点(entities)-边(relations)-属性(properties)”天然表达语义关系的NoSQL存储。
节点代表人、物、事件等对象
边表示两节点间的关联(如“雇佣” “供应” “引用”等),可带属性
属性是节点或边携带的键值对信息
与传统关系型数据库表结构相比,图数据库极其适合层层关联的复杂查询(如链式追踪、找最短路径),尤其适合多层关系和实时查询需求。
知识图谱概念
知识图谱是在图数据库基础上的结构化知识组织形式,注重本体定义(即实体和关系的种类、规则)、丰富的关系刻画、推理能力及跨源数据融合能力。
强调多样关系(如层级、因果、时序、空间等)
支持“本体+事实+规则”三元组结构,精准刻画复杂知识世界
可与文本、关系型、半结构化等多源数据整合
例如:
(Alice:员工) -[精通]-> (Python:技能)
(Alice:员工) -[参与]-> (Phoenix:项目)
(Phoenix:项目) -[管理部门]-> (RnD:部门)
(SpecDoc:文档) -[提及]-> (Python:技能)
图查询语句如:
查询R&D部门中精通Python并参与Project Phoenix的员工
查询Phoenix项目关联的所有文档及其涉及技能
4.GraphRAG:大模型检索的“关系觉醒”
GraphRAG突破了传统RAG孤立文本检索的局限,将大语言模型与知识图谱深度融合,支持关系感知检索生成。
核心理念
中心原则:关系感知的检索(Relationship-Aware Retrieval)
GraphRAG不仅基于语义相似性寻找节点(实体),而是:
解析意图与实体,并“锚定”到知识图谱的相关节点
利用图数据库进行多跳关系检索或提取子图
结合实体属性的向量语义检索与结构化关系遍历
将提取的结构化信息转换为LLM可处理的文本上下文,构造完整思考链路
典型处理流程
1.用户输入自然语言问题
2.查询解析与实体消歧,定位图谱节点
3.图检索:多跳遍历、子图提取、关系过滤
4.上下文序列化,智能压缩嵌入Prompt
5.LLM利用结构上下文推理生成答案
6.呈现结果
【此处可配合图示:GraphRAG流程环节与传统RAG对比】
5.GraphRAG核心机制与技术细节
图构建与知识注入
数据源识别、实体挖掘(NER)、关系抽取,建议先设计本体(schema/ontology)
ETL流水线、实体消歧、图谱补全,可串接外部权威知识库(如Wikidata等)图嵌入与向量检索(表格一:GraphRAG嵌入类型)

嵌入用于:支持节点/子图的语义检索、相似度计算、聚类分析等
向量/图数据库混合存储与索引(表格二:GraphRAG存储选型)
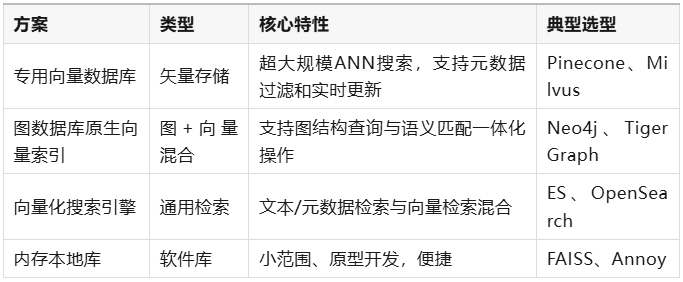
图驱动检索策略
- 实体驱动: 按查询发现关键实体后,起点检索其关联邻居节点
- 关系遍历: 顺着指定类型的边递归查找,如“部门->项目->员工”
- 路径查找、子图提取、社区检测
- 混合检索: 先用语义相似性搜种子节点,再遍历其图结构拓展上下文
上下文增强与Prompt工程
- 结构化信息需“线性化”为文本进入LLM,可采用模板/Path/NLG小模型/JSON/Markdown格式,兼顾Token高效利用
- Prompt设计需明示信息来源,指示模型如何利用结构上下文,辅以示例
6.GraphRAG能力突破:关系驱动的智能进阶
上下文理解力极大提升
图结构检索不再依赖关键词,而能为LLM提供包含全链路关系的上下文。高质量子图还原“事实网络”,便于模型做出深度、具解释性的回答。
天然支持复杂多跳推理
利用原生图遍历,实现多步逻辑链路题(如合作链、供需链、引用链),LLM基于明晰路径再生成解释,无需“脑补”信息缺口。
幻觉大幅降低
知识图谱常作为权威事实集,检索时清晰指定实体、属性与关系有效约束模型,输出与知识基事实强绑定。
支持关系驱动复杂查询
如“供应商A中断将如何影响产品B成本?哪些环节受影响?”等,需要沿整个图谱链路追溯,GraphRAG可还原因果与影响路径。
7.实践路线:GraphRAG六步构建法
1.数据基础 :聚合结构化、半结构化、非结构化源,明确目标域及检索范围
2.知识图谱构建 :本体设计、实体与关系抽取、消歧与命名映射、数据加载与质量校验
3.嵌入与索引 :生成/引入节点与文本嵌入,存入向量或图数据库
4.检索逻辑开发 :查询解析、实体锚定、关系多跳/混合检索、超参数优化
5.大模型集成与Prompt优化 :上下文“线性化”、Prompt模板、与模型API对接、答案格式加工
6.评测与迭代 :自建问答集合,突出多关系/多跳任务,量化检索质量、准确率、支持度、完整度等
8.行业典型应用场景
1.复杂档案/法规/科研问题智能问答
如法律案例溯源、科学文献引用推理、金融合规穿透分析等,问法多依赖等级、引用、多实体链路,GraphRAG可结构化串联关键节点
2.个性化推荐引擎
如电商/内容平台/社交网络,将用户、物品、行为及属性构入图谱,支持多跳互动与关系洞察式推荐
3.科研发现与药物开发
整合基因、蛋白、疾病、药物多表型图谱,为药物重定位、并发机制等复杂检索与假说生成提效
4.智能风控反欺诈
构建账户、交易、组织、设备、恶意模式间的图谱,检索多阶复杂环,精准锁定潜在风险
5.智能供应链分析
描摹“供应商-物料-产品-渠道”全连接,按事件沿链路追溯影响,支持风险应急与优化
6.客户360画像与关系情报
B2B/B2C均可将触点、交互、组织关系一体化汇聚,为客户洞察与交叉销售赋能
9.未来挑战与研究前沿
可扩展性
大规模知识图谱检索与子图嵌入实时生成需求高,需优化分布式图库、图分区与硬件协同
图谱构建与演化
多源复杂实体及关系抽取难度大,自动化/半自动化构建、版本演进、实时更新、众包等仍需突破
动态时序与增量处理
需支持“时序知识图谱”,持续接入和冲突分辨能力提升
评测标准化
多模态、关系丰富图谱的检索与生成联评标准尚未统一,未来需开发专用RAG评测数据集与追踪表征
解释性与混合检索融合
如何让LLM明确“用到哪些关系路径生成了答案”,以及深度融合向量、稀疏检索信号,是接下来技术演进的重点
多模态知识融合
拓展更广泛的视听图谱与跨模态共检索,将是下阶段GraphRAG升级方向
10.GraphRAG与其他检索增强技术横向对比
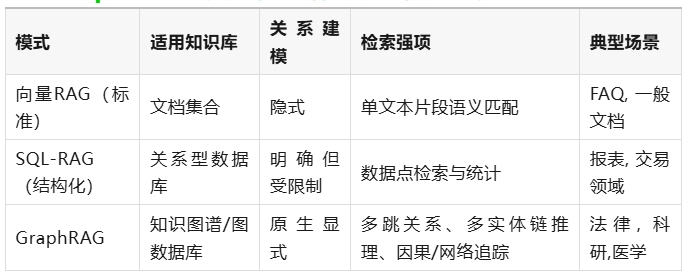
GraphRAG显著优势在于:当问题本质关注多实体间复杂关系和路径时,图结构比SQL多表连接更自然高效。



