首页>博客>应用分享>Demo 介绍|图技术在保险反欺诈领域有哪些应用?
Demo 介绍|图技术在保险反欺诈领域有哪些应用?
购买保险是大众管理自身风险的重要手段;而对于保险行业及其监管机构来说,如何管控保险公司自身的 “风险” 也至关重要。
本期就让 悦数图数据库 的解决方案专家 阿党 带你从图(Graph)的角度一探究竟
背景介绍
传统风控主要靠人工审核和经验判断,近十年来随着数字化的兴起,头部公司开始引入黑名单系统,通过简单规则和事后稽查来填补审查阶段遗漏的风险点,但这样依然无法提前发现问题。而从 2018 年开始,反欺诈系统逐渐发展到以规则引擎、实时指标计算以及机器学习等技术组成的“智能决策引擎”阶段。
保险欺诈管控痛点
纵观当前的保险行业,大家关注的风控痛点可以归纳为以下几个方面:
信息割裂导致风控效果不佳:保险公司及相关的行业数据存储比较割裂,甚至同一个保险公司内部的各个系统间的数据也是烟囱式的。这就会造成业务信息的不对称,并由此引发虚假理赔案件,或者利用信息不对称来提高理赔金额。
立体多维计算的要求:行业欺诈多样性、专业化、团体化的特征,会倒逼反欺诈系统融合各方数据进行立体多维度的数据分析,而传统基于关系模型 / 维度模型 / 宽表建模的分析系统在几十甚至更多维度的场景下是很难支撑的。
算法识别的精准度要求:业务模型调优需要在训练和 serving 阶段能够输入更多的特征数据。一般有两种方法,一是更多的数据量来喂,一个是关联数据的补充。但如果用传统方法去做,4 跳以上的预测关系输入就会很困难,时效性也跟不上。
底层存储面临的挑战
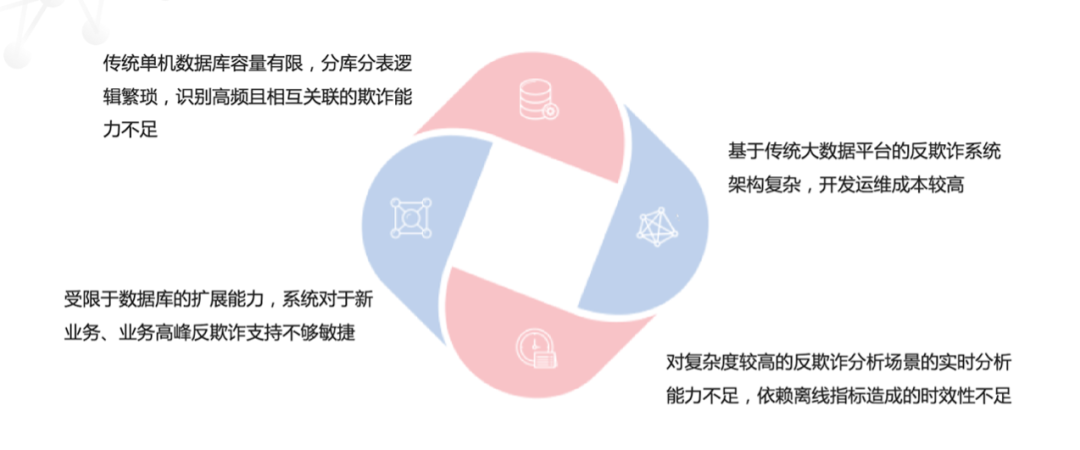
随着反欺诈系统的变革和数字化进展,反欺诈系统在底层存储支撑系统上也面临着一些挑战。
传统单机数据库在容量和针对关联数据的查询上,性能是有瓶颈的。另外在可扩展性上,业务的更迭以及波峰波谷对于数据库的扩展能力是有敏捷性要求的。现在的风控系统大部分都是采用 Hadoop 生态建设的,包含着很多组件来组合完成系统目标,对应的开发和运维的成本都会偏高。另外,在实时数据分析方面,多源数据融合带来的多维数据分析需求,靠传统大数据平台是很难支撑的。
这里有一个真实的数据,西南一个市的医保系统数据日新增 5G,存量 100T,这就要求底层系统能够满足大规模数据的存储和查询。
应用场景
目前,悦数图数据库在保险反欺诈的多个方面都有应用,下面介绍 5 个常见的场景,供大家参考。
场景 1:关系发现
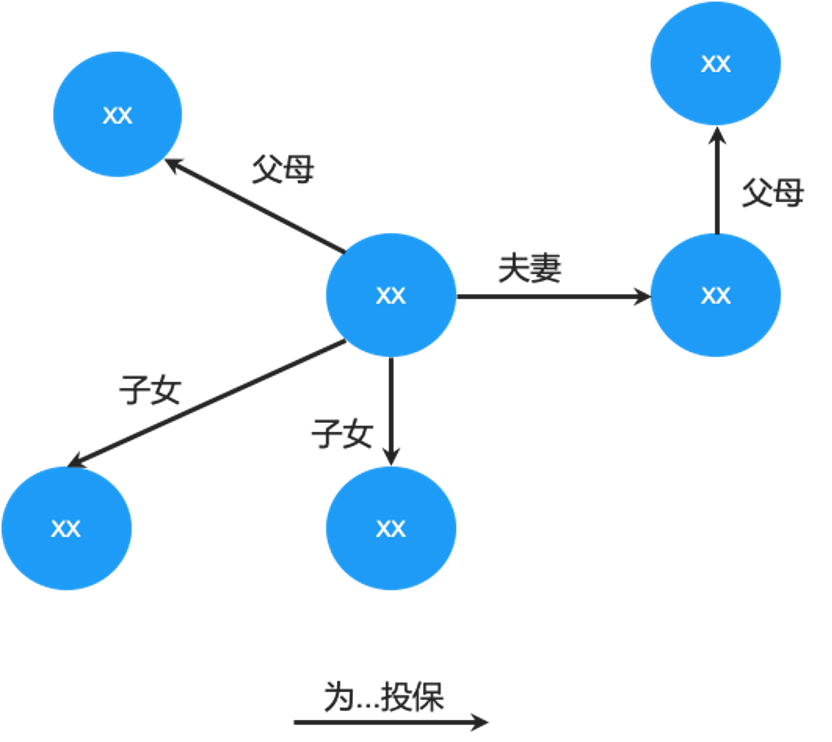
客户在填写投保相关表单的时候会存在漏填甚至不填的情况,对于这种不确定或者缺失的关系通过原有方法并不能很好地做出判断。图数据结构能够让我们充分利用它的寻路功能,这是其他类型数据库并不原生支持的。
另外,常规表单里只填写直系亲属,体现不出间接关系。在 悦数图数据库 中,可以通过现有数据发现更多的隐藏关系,包括一些群体化的特征和更多社会和非直系亲属的家族关系,对保险行业来说,就可以对这个家族购买保险的情况进行全面的画像分析。
场景 2: 欺诈发现
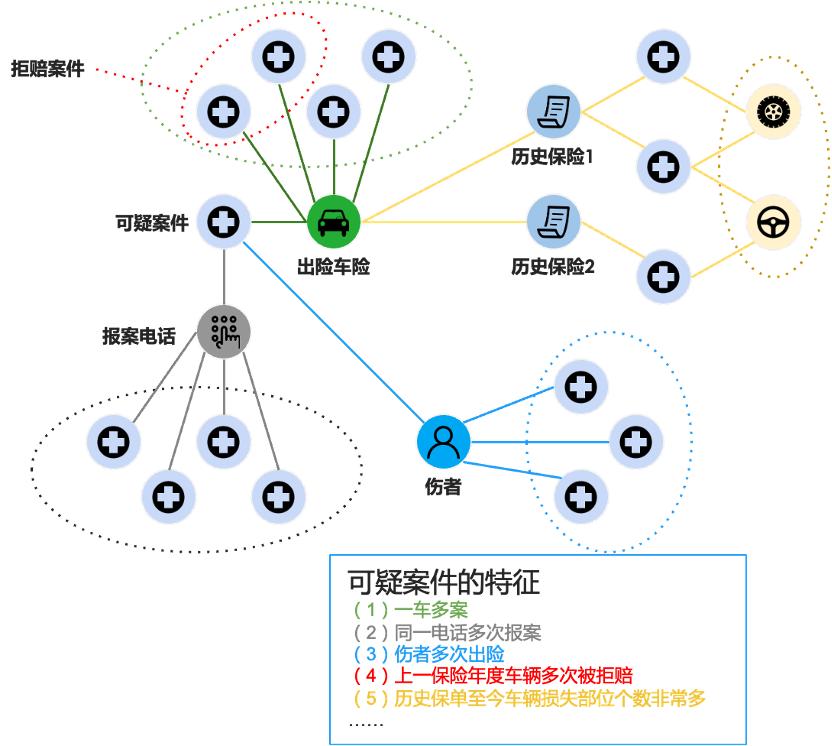
传统的欺诈检测大都基于经验规则,无法去识别潜在的欺诈行为。
以车险为例,车险中涉及到的实体相对来说较多,包括车辆、车主、司机、乘客等等,在这些信息中进行有效识别是一件非常难的事件。但是在图数据库中,可以通过构建图谱,根据理赔数量或者其他业务指标来看一些异常值,也可以通过图算法去划分欺诈率较高的群体,在社会关系网络中,可以看与黑点的关联度来判断欺诈可能性。总体来说,可以充分利用图数据库中的模式匹配等技术,在这些实体构建成的赔付图谱里运用算法技术去对主要的角色做社群划分,然后基于业务经验和已有的欺诈案件去识别欺诈率比较高的群体或者个体。
另外,欺诈案件通常都会有一定的特征。例如一辆豪华的二手车经常有事故发生或者某个人频繁驾驶不同的车辆出现多起事故,或者不同车辆群体和多个车主的关联度高,而且出现多起事故,这些都是可疑的欺诈案件特征,都可以通过图技术快速有效地识别。
场景 3: 营销协同推荐
下面说说业务场景,在营销推荐场景中,可以在图数据库中建立客户的一张关系大图来更立体地识别客户,通过客户留存的一些个人信息可以基于社区发现等算法去识别除了常见直系亲属以外的社会关系,补充家族、朋友等各类关系,这种关系网络的建立可以帮助我们看到更大维度的社会关系。例如通过客户留存的信息进行连接,可以在不同的客户的联系上发现更多的隐藏关系,推理出更多社会关系,可以进而刻画家族购买保险的情况。
在保险公司私域场景下,营销代理人就可以通过客户或其关系网络已经购买的保险组合去推荐其他的保险产品,存在关联关系的群体可能倾向于某一种保险组合,从另外一个角度来说,这种关联推荐对于客户会更有说服力。在公域场景的精准获客上,图数据库也可以助力客户数据系统,丰富广告投放人群包,进行产品的营销投放。
场景 4: 承保 & 理赔反欺诈
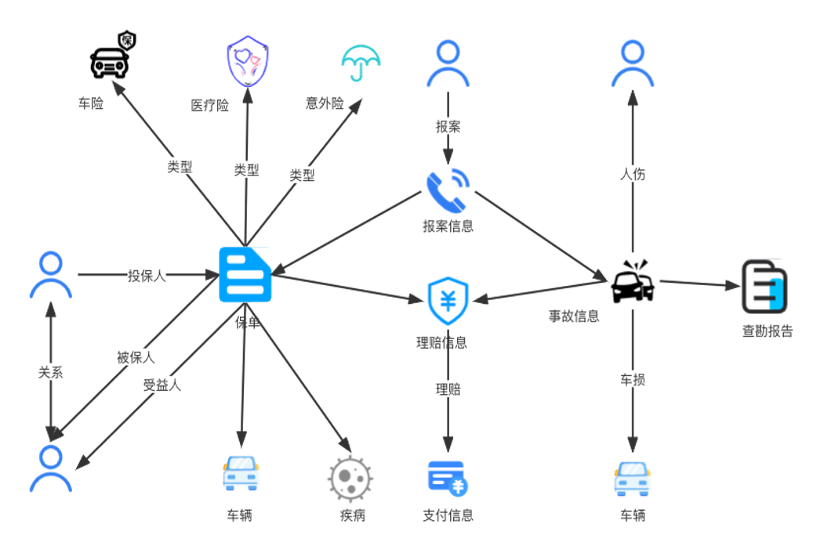
承保和理赔阶段可以去看出入度,去看被保险人有哪些保险,被拒赔了多少次,跟已知欺诈案件的关联等等。上面是一张大概的图谱,从车险这个角度来说,结合刚才有讲到的欺诈发现,应用图谱可以由单纯的“从案件角度”发展为“从案 + 从人 + 从车”的多维度分析。例如在酒驾调包风险(指客户 A 酒驾发生事故后,联系其亲友 B 赶到现场并顶替 A 向保险公司报案,以获得保险赔偿)中,将通过分析当事人主被叫关系、定位信息等行为数据,会得到延迟报案、 非常用手机号、距离现场位置等多个风险因子。
场景 5:代理人核验管理
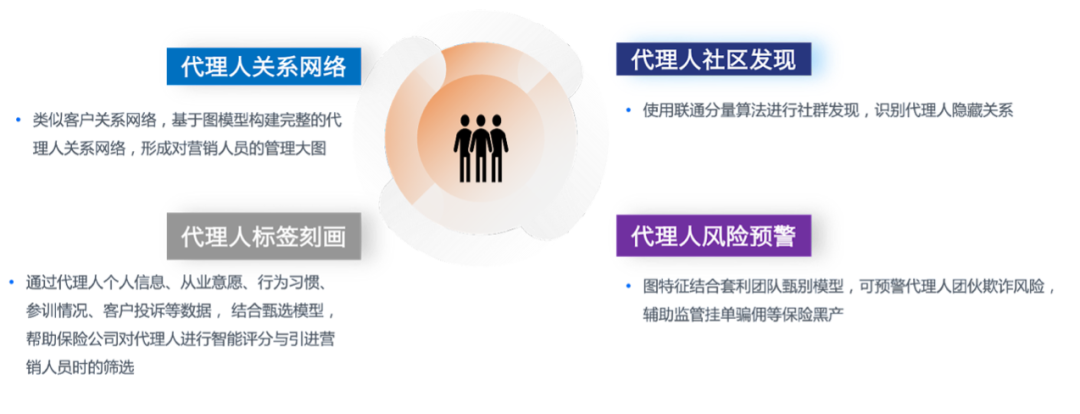
国内保险代理人数众多且流动率高,会导致保险公司面临人员操作与合规风险。
我们同样也可以基于图模型去建设代理人的关系网络,可以通过代理人的职业习惯、投诉情况等进行标签刻画,从源头上加强对代理人的筛选。对于一些保险黑产,例如伪造新人身份挂单骗佣的场景,可以通过手机号、电子设备号、IP 关联等手段识别欺诈风险,都可以有效降低由代理人引发的客户投诉及骗保等行为。
为何选择 「悦数图数据库」?
产品特性
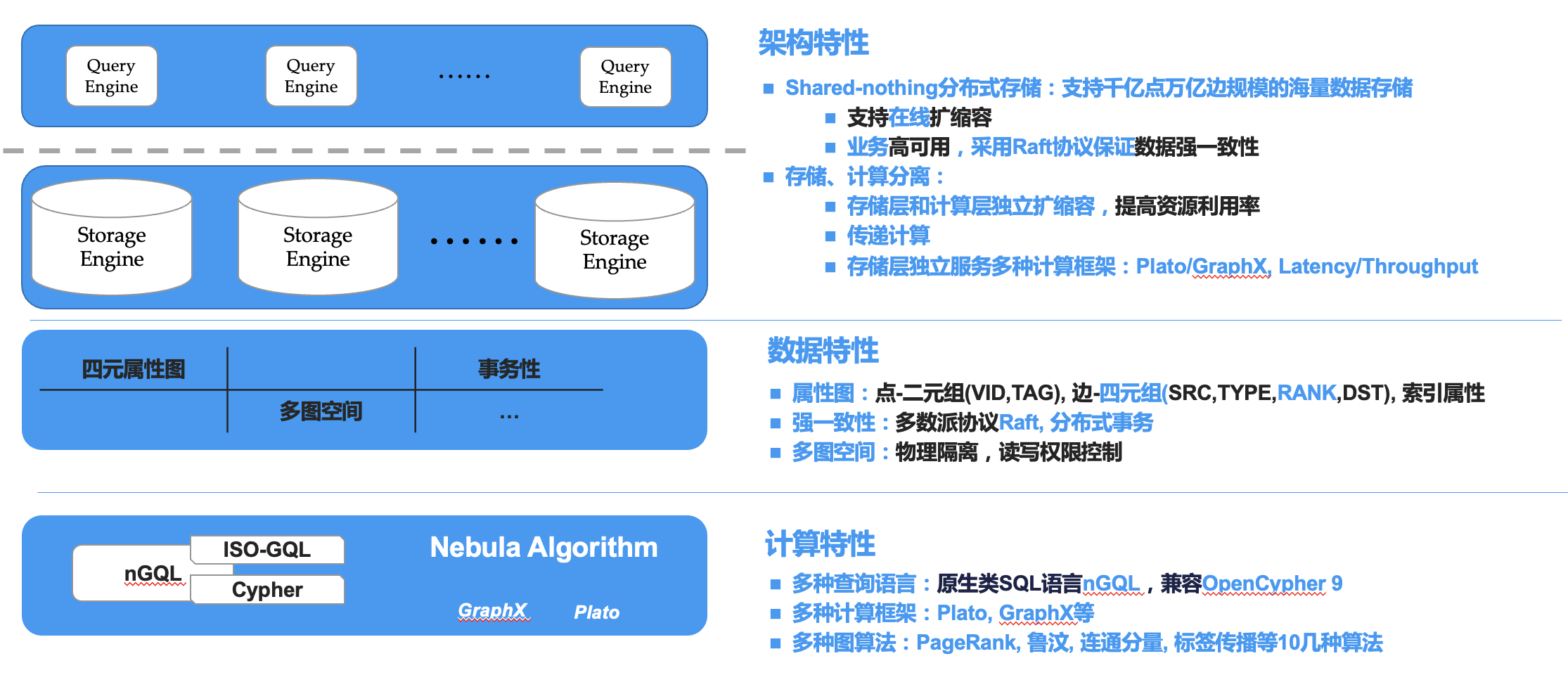
针对以上介绍的反欺诈痛点和系统层面的建设需要, 我们梳理了 悦数图数据库 产品上的 6 个特征,可以满足保险风控场景的需求:
1. 多源数据融合:保险数据往往来自于银行、互联网、政府、医疗、运营商等多个方面,结合保险公司的数据整合对接后形成风险信息库,就能建立对客户的全方位分析,才能更好地帮助保险公司实现自动和精准的核保。
2. 支持图数据模型:数据最底层模型的建立对于后续的多维度分析至关重要,悦数图数据模型本身天然贴合关联数据的存储和查询展示要求,在 Schema 灵活的同时能够提供相较关系模型更好的分析时效。
3. 云原生架构:一个好的存储系统可赋予上层应用更多的敏捷性,根据业务需要去做计算和存储的横向扩展。悦数图数据库是一款分布式的云原生图数据库,这就能很好地解决弹性上的问题。
4. 企业级特性支持:作为基础软件,悦数图数据库会提供周边工具的支持,来让业务人员更好地做探索,让运维人员做可视化的运维。
5. 风险因子的挖掘:通过 悦数图数据库 在关联分析场景的检索优势,结合一些图计算引擎,可以更好地去用算法去识别风险和挖掘风险因子。
6. 辅助算法精准度:机器学习依赖通过元组构建的输入数据,容易忽略了预测关系类的数据,可以利用图特征的输入来丰富上下文信息进而提升相关模型的准确度。
综上,使用 悦数图数据库可以把多维度的数据连接起来,方便业务更好地应用和探索不同场景,有效规避保险各环节隐藏的风险。
附上本次分享的视频,欢迎大家 点击 查看~



