首页>博客>行业科普>GraphRAG超越传统RAG:突破知识密集任务的AI新范式
GraphRAG超越传统RAG:突破知识密集任务的AI新范式

研究背景
1.研究问题:这篇文章要解决的问题是如何在检索增强生成(RAG)系统中有效利用图结构来提升大型语言模型(LLMs)的性能,特别是在知识密集型任务中。
2.研究难点:该问题的研究难点包括:现有基准测试未能充分评估图结构在RAG系统中的有效性;现有数据集缺乏领域特定知识和明确的逻辑连接;现有基准测试的任务复杂度划分不细致,无法全面评估模型的复杂推理能力。
3.相关工作:该问题的研究相关工作有:传统的RAG系统通过将文本分块进行索引和检索,但这种方法会牺牲上下文信息;GraphRAG系统通过构建外部结构化图来改进LLMs的上下文理解能力,但其在实际任务中的表现不一致。
研究方法
这篇论文提出了GraphRAG-Bench,用于评估GraphRAG模型在层次化知识检索和深度上下文推理中的表现。
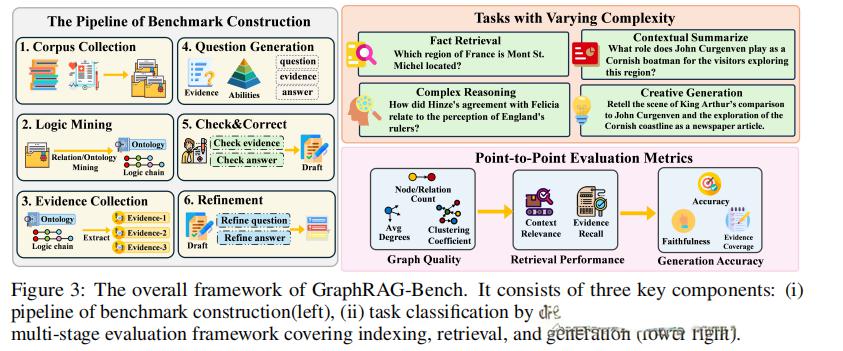
具体来说
1.任务形式化:设计了四个不同难度的任务,从事实检索到创意生成,逐步增加检索难度和推理复杂性。
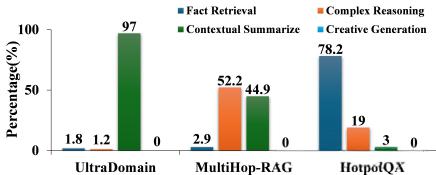
2.数据集构建:构建了两个数据集,一个是医学指南数据集,包含明确的层次结构和标准化协议;另一个是19世纪小说数据集,包含隐式的非线性叙事。
3.逻辑和证据提取:使用GPT-4.1将原始文本转换为结构化的领域本体,保留实体及其上下文关系和层次依赖关系。
4..问题生成:根据证据的类型生成问题,从孤立子图的检索到全局拓扑感知的综合推理。
5.相关性检查和精炼:实施严格的验证和精炼过程,确保数据集的准确性和实用性。
实验设计
1.数据收集:从国家综合癌症网络(NCCN)临床指南和Project Gutenberg图书馆收集了医学指南和小说数据集。
2.实验设计:设计了四个不同难度的任务,并在每个任务上评估了多种GraphRAG框架和传统RAG系统的表现。
3.样本选择:选择了医学指南和小说数据集中的样本,确保数据的多样性和代表性。
4.参数配置:在实验中保持了统一的条件,所有系统使用相同的嵌入模型和生成温度,以公平比较各系统的性能。
结果与分析
1.生成准确性(Q1):在简单事实检索任务中,基本RAG与GraphRAG的表现相当或更优;在复杂任务中,GraphRAG表现出明显的优势,特别是在复杂推理、上下文总结和创意生成任务中。
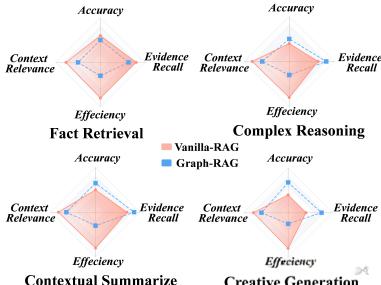
2.检索性能(Q2):在简单问题中,RAG在检索离散事实方面表现优异;在复杂问题中,GraphRAG在连接远距离文本片段方面表现出色。
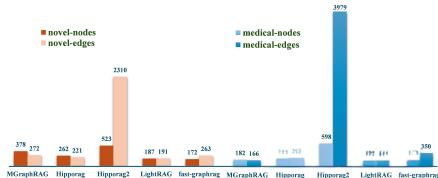
3.图复杂性(Q3):不同GraphRAG实现生成的索引图在结构上存在显著差异,HippoRAG2生成的图密度最高,节点和边数最多,改善了信息的连接性和覆盖率。
4.效率(Q4):GraphRAG由于涉及额外的知识检索和图聚合步骤,显著增加了提示长度,特别是在复杂任务中,提示长度的增加可能导致冗余信息的引入,从而降低上下文相关性。
总体结论
这篇论文系统地研究了GraphRAG在哪些条件下能够超越传统RAG,并提供了其实际应用的指导。通过提出GraphRAG-Bench,论文为评估GraphRAG模型提供了一个全面的基准测试,揭示了图结构在不同任务中的潜在优势。尽管GraphRAG在复杂任务中表现出色,但在简单任务中可能会引入冗余信息,影响效率。未来的研究可以扩展到多模态数据的评估,进一步验证GraphRAG在异构知识表示中的应用效果。



