首页>博客>行业科普>从“指标黑盒”到“秒级溯源”:一家车企如何重构数据信任
从“指标黑盒”到“秒级溯源”:一家车企如何重构数据信任

业务背景
在数字化转型的浪潮中,汽车行业的竞争早已从“马力”转向“算力”。数据,正成为车企营销、研发、供应链决策的核心燃料。但一个普遍的尴尬现实是:数据越多,信任越少。
某头部自主品牌就曾深陷这样的困局——当业务团队发现“2023 年 7 月中型 SUV 销量”数据异常时,没人能说清这个数字究竟来自经销商系统、CRM 系统,还是中间数据平台的加工结果。而当他们想查“2024 年 1–7 月插电混动车型分区域线索转化率”时,却要跨系统取数、写 SQL、等排期,4 小时后才拿到结果,早已错过当日策略调整的最佳时机。
这不是孤例,而是许多企业在数据应用中的“通病”:
- 指标溯源难——数据从哪来、怎么算的,没人说得清;
- 分析响应慢——临时需求依赖开发,动辄数小时甚至数天;
- 业务不信任——因为看不懂、查不到,最终回归“凭经验拍脑袋”。
问题的根源:数据在“黑盒”中流转
为什么会出现这些问题?
根本原因在于:数据资产缺乏语义关联与链路透明性。
指标的计算逻辑、依赖字段、流转路径长期隐藏在系统“黑盒”中,业务人员看不懂,技术人员讲不清。这不仅导致沟通成本高昂、重复劳动频发,更让数据的可信度大打折扣——当数据无法被验证,它就失去了作为决策依据的价值。
要破局,就必须打破“黑盒”,让每一条数据的来龙去脉都清晰可见。
破局之道构建指标血缘图谱与智能问答 DataGPT
要让数据从“黑盒”变“透明”,这家车企找对了方向:围绕业务语义建指标血缘图谱,再配上面向业务人的智能问答工具(DataGPT),三步就打通了数据用起来的 “堵点”。
1、统一语言:业务语义映射
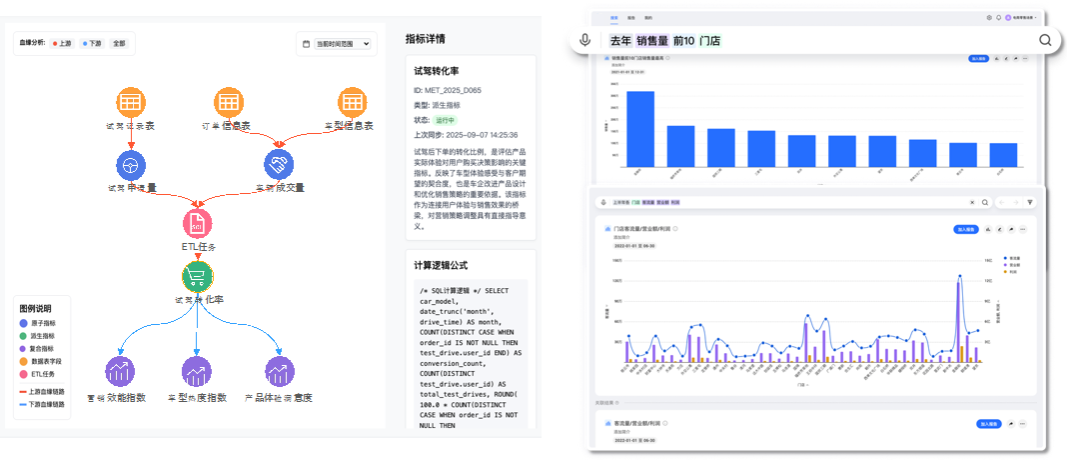
首先,他们梳理了营销域的核心业务术语,建立了“业务指标—技术指标—物理字段”的三层映射关系。比如,“试驾转化率”不再是一个模糊的概念,而是明确对应到某个数据表、某个字段、某段计算逻辑。这一步,解决了业务与技术之间的“语言断层”,让双方终于能“说同一种话”。
2、透明链路:全链路血缘解析
通过自动化采集 ETL 任务、BI 报表脚本、数据模型等元数据,系统构建了从原始数据源到最终报表的全链路血缘图谱。每一个指标,都能清晰展示其数据来源、加工路径、依赖关系。过去需要翻日志、查文档的溯源工作,如今只需一键穿透,秒级定位问题源头。
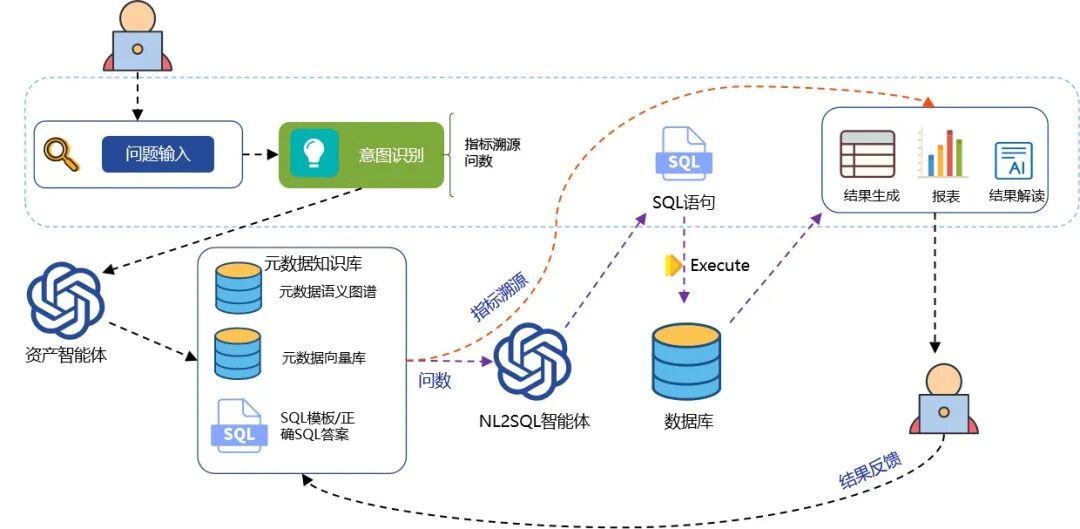
3、智能交互:DataGPT让“问数”像聊天一样简单
基于血缘图谱,他们嫁接大模型能力,打造了面向业务人员的智能问答系统(DataGPT)。业务人员只需输入:“上海Q3的试驾转化率是多少?”系统便能自动解析语义,匹配指标,执行查询,并返回结果及数据来源、计算逻辑、变更历史。无需SQL,无需排期,无需等待。
数据血缘建设的“技术密码”四层架构构建坚实底座
构建可追溯、可理解、可复用的数据血缘体系,离不开一套完整的技术架构。这家车企的技术架构就像一座坚固的“数据大厦”,由四层构成:
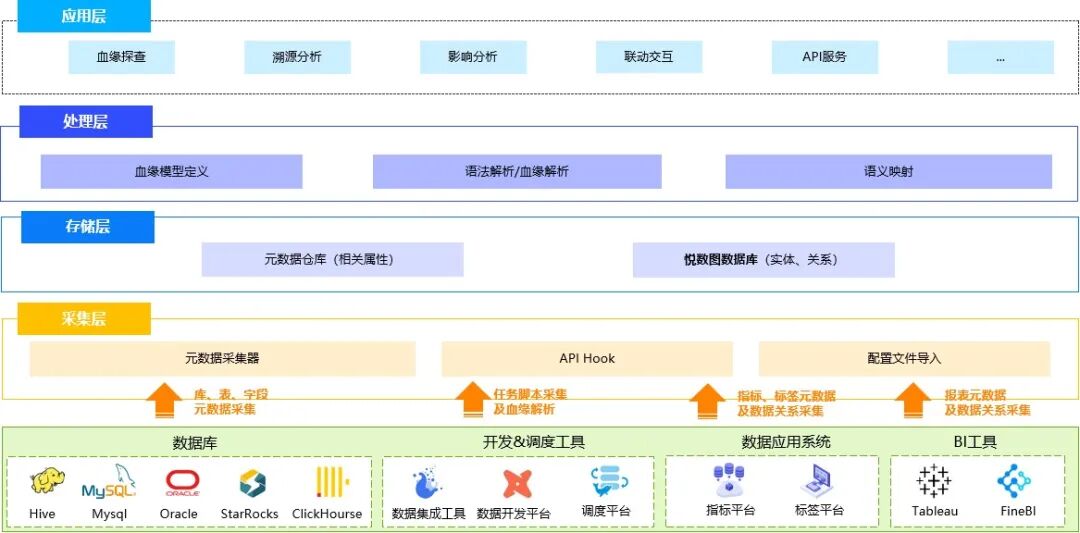
1、数据采集层
通过元数据采集器、API Hook、配置文件导入等多种方式,自动化采集来自数据仓库、ETL 工具、BI 平台、数据模型的结构与语义信息,实现多源异构系统的全量接入。
2、处理层
对采集数据进行标准化处理,包括血缘模型定义、语法解析、字段级依赖推导与业务语义映射。其中,业务指标与技术字段的语义对齐是关键环节——必须将“试驾转化率”“线索成本”等业务术语,精准映射至底层表、字段、计算逻辑,形成统一的语义锚点。该层完成三项核心工作:
业务语义映射:梳理营销域核心指标,建立“业务指标—技术指标—物理字段”的三层映射关系,确保术语在业务与技术端语义一致;
全链路血缘解析:识别指标从原始数据源经ETL、聚合、建模至报表输出的完整路径,构建端到端依赖关系;
智能问数语义解析:将自然语言查询(如“上海 Q3 试驾转化率?”)转化为可执行的技术指标与过滤条件,实现语义到查询的自动转换。
3、存储层
采用悦数图数据库作为核心存储引擎,将实体(指标、字段、任务、表)与关系(依赖、计算、流转)以原生图结构存储,支持毫秒级多跳路径查询、动态关系遍历与大规模图谱更新。凭借悦数图数据库的高并发、低延迟与 GQL 原生支持能力,使复杂血缘关系的实时探查成为可能。
4、应用层
基于图谱构建溯源分析、影响分析、智能问数、血缘可视化等能力,实现业务人员通过自然语言直接获取数据来源、计算逻辑与变更历史,完成从“问数”到“见源”的闭环。智能问答系统与数据目录、权限体系、可视化面板深度集成,为业务人员提供一站式数据消费体验。
从被动到主动:血缘体系带来的数据赋能
当血缘体系落地,企业数据使用方式发生根本性转变:
指标溯源由人工翻日志、查文档,转变为一键图谱穿透,响应时间从数天降至秒级;
临时分析需求不再依赖开发排期,业务人员通过语义问答直接获取结果,响应周期由周级压缩至半天内;
数据团队的重复性工作减少 85% 以上,资源得以释放至建模优化与数据治理;
业务侧主动用数率提升 300%,数据驱动决策机制逐步形成。
更重要的是,数据可信度获得实质性提升。业务人员不再依赖口头确认,而是通过可视化血缘图自主验证来源与逻辑,形成“可追溯、可验证、可审计”的数据消费闭环。
经验总结:少走弯路的“智慧锦囊”
价值驱动敏捷切入:从业务痛点最集中的营销场景入手,采用小步快跑的方式,快速交付可见价值,从而赢得业务侧的信任与支持。就像盖房子一样,先打好地基,再一层一层往上盖,稳扎稳打。
业务语言是桥梁:优先梳理业务术语和指标的映射关系,这是实现“业务与技术对话”的基础。只有双方说同一种“语言”,才能更好地合作。
体验至上:面向业务人员的工具必须做到极致简单、直观,实现“开箱即用”。就像使用智能手机一样,无需复杂的操作,就能轻松上手,这样才能真正降低使用门槛,推动数据驱动文化的普及。
行业启示:数据血缘不止是技术,更是数据治理的 “地基”
数据血缘不仅是技术组件,更是企业数据治理的基础设施;其缺失将导致指标来源不明、链路不可追溯,不仅削弱决策可信度、抬高运维成本,更使企业在《数据安全法》《个人信息保护法》等合规要求下面临审计风险与重复建设的资源浪费。
通过悦数图数据库支撑的血缘体系,企业可以实现数据的可见性、可理解性与可问责性,为数据资产的高效运营与合规治理提供了底层支撑。在数据驱动转型的深水区,技术的价值不在于工具的先进,而在于能否弥合业务与技术之间的认知鸿沟。数据血缘体系的建设,本质是构建一套企业级的数据语言系统——让指标不再沉默,让链路不再模糊,让每一次查询都有据可循。
关于海南数造科技
海南数造科技有限公司成立于 2015 年,是国内领先的数据开发治理平台提供商。公司以“DATA+AI”双引擎驱动,为政企提供敏捷的一站式大数据研发和治理能力,产品和服务涵盖数据建模、 数据目录、 数据开发、数据治理、数据运营及数据交易等关键环节。数造科技致力于助力各级政府与企业深入推进数字化转型,累计为金融、零售、制造、能源、政务、医疗等多个行业上百家客户提供产品和服务,引领数据智能领域创新发展。
关于悦数图数据库
悦数图数据库是杭州悦数科技有限公司开发的一款企业级原生分布式图数据库,100% 国产自研,拥有多项核心专利和技术认证。悦数图数据库是全球首家原生支持 ISO-GQL 的分布式图数据库产品,采用 Shared-nothing 分布式架构和计算与存储分离的设计,擅长处理千亿点万亿边的超大规模数据集并保持毫秒级查询延时,具有高可用、高安全、易扩展的特点,能够满足企业两地三中心、三地五中心等多地容灾的安全性需求,并且能提供公有/私有化等多种灵活部署方式。来自各行业的众多头部企业和机构用户在生产核心系统使用悦数图数据库,用于实时推荐、实时风控、欺诈检测、知识图谱等业务场景和需求。



