首页>博客>行业科普>AI进化论:知识图谱加持下的大模型革命
AI进化论:知识图谱加持下的大模型革命

AI 随着 GPT-4 等大型语言模型 (LLM) 的蓬勃发展,它们可以生成令人印象深刻的类似人类的文本。然而,他们有一个大问题:幻觉。LLM 可以自信地得出完全错误或虚构的答案。当准确性很重要时,这是有风险的。
但有一个解决方法:知识图谱。他们将信息组织成相互关联的事实和关系,为 LLM 提供坚实的事实基础。通过将知识图谱与 LLM 相结合,我们可以减少幻觉并产生更准确、上下文感知的结果。
这种强大的组合为高级应用程序打开了大门,例如基于图谱的检索增强生成 (RAG)、AI Agent之间顺畅的团队合作以及更智能的推荐系统。
让我们深入了解知识图谱如何解决 LLM 的问题并改变 AI 世界。
了解知识图谱
什么是知识图谱?
知识图谱是信息的结构化表示形式,通过实体及其关系对现实世界的知识进行建模。它们由节点 (实体) 和边缘 (关系) 组成,形成一个反映不同信息如何互连的网络。
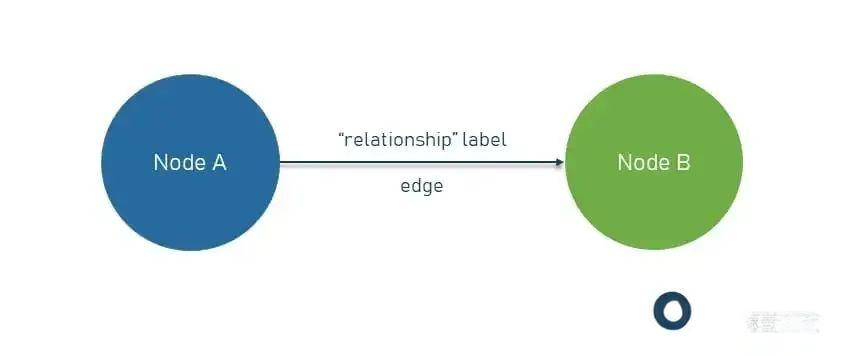
- 实体(节点)
这些是表示现实世界对象或概念的基本单位。示例包括像 “Marie Curie” 这样的人,像 “Mount Everest” 这样的地方,或者 “光合作用 ”这样的概念。
- 关系 (Edges)
这些说明了实体是如何连接的,从而捕获了它们关联的性质。例如,“居里夫人”发现“钋”或“珠穆朗玛峰”位于“喜马拉雅山”。
通过以这种方式组织数据,知识图谱使系统不仅能够理解孤立的事实,还能够理解它们之间的上下文和关系。
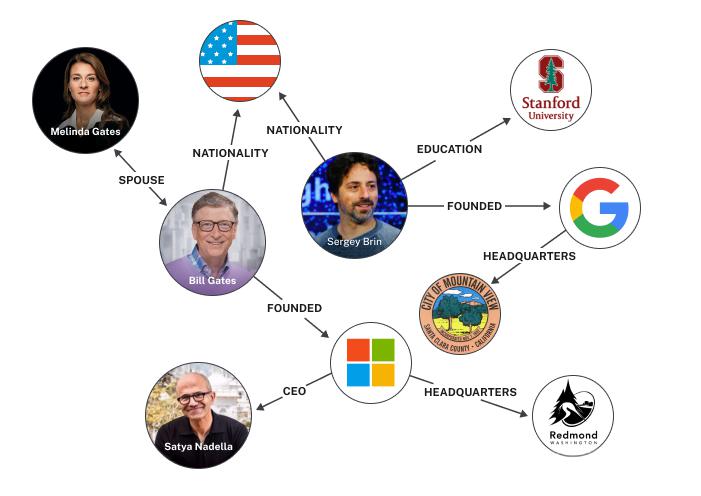
知识图谱示例:
Google 的知识图谱, 通过直接在搜索页面上提供有关实体的即时答案和相关信息来增强搜索结果。如果你搜索“阿尔伯特·爱因斯坦”,你会看到他的生平总结、主要作品和相关人物。
Facebook 的社交图谱, 代表用户及其联系,对朋友、兴趣和活动之间的关系进行建模。这使 Facebook 能够有效地个性化内容、推荐朋友和定位广告。
知识图谱与矢量数据库有何不同?

知识图谱和矢量数据库以完全不同的方式表示和检索信息。
知识图谱将数据构建为实体(节点)及其显式关系(边缘),使系统能够了解事物是如何连接的并对这些信息进行推理。它们擅长提供上下文、执行逻辑推理以及支持涉及多个实体和关系的复杂查询。
另一方面,向量数据库将数据存储为高维向量,这些向量捕获信息的语义含义,专注于基于相似性的检索。虽然向量表示非常适合通过非结构化数据(如文本或图像)进行快速、可扩展的搜索,但它们缺乏知识图谱提供的明确、可解释的连接。
简而言之,知识图谱通过清晰的关系提供更深入的理解和推理,而矢量数据库则针对快速、基于相似性的搜索进行了优化,而无需了解项目之间的关系。
将知识图谱与 LLM 框架集成
通过将知识图谱与 LLM 应用程序框架集成,我们可以释放强大的协同作用,从而增强 AI 能力。知识图谱为 LLM 提供结构化的事实信息和实体之间的明确关系,使模型建立在现实世界的知识基础上。
这种集成通过为 LLM 提供可靠的参考来生成准确且上下文感知的响应,从而有助于减少幻觉。

因此,将知识图谱与 LLM 集成为各种应用程序开辟了一个充满可能性的世界。
应用 1:基于图的检索增强生成 (RAG)
基于图检索的增强生成,通常称为 GraphRAG,是一种高级框架,它将知识图谱 (KG) 的强大功能与大型语言模型 (LLM) 相结合,以增强信息检索和文本生成过程。
通过将图中的结构化知识集成到 LLM 的生成功能中,GraphRAG 解决了传统 RAG 系统的一些固有局限性,例如幻觉和肤浅的上下文理解。
首先了解 Retrieval-Augmented Generation (RAG)
在深入研究 GraphRAG 之前,必须了解检索增强生成 (RAG) 的概念:
RAG 将检索机制与生成模型相结合,以产生更准确且与上下文相关的响应。
在传统的 RAG 系统中,当 LLM 收到查询时,它会使用相似性搜索(通常基于向量嵌入)从语料库中检索相关文档或数据块,并将该信息合并到响应生成中。
传统 RAG 的局限性:
浅层上下文理解
RAG 严重依赖检索到的文档的表面文本,而没有对内容进行深入推理。
幻觉 由于缺乏结构化的事实基础,LLM 可能会产生听起来似乎似乎不正确或荒谬的答案。
隐式关系
传统的 RAG 无法有效地捕获实体之间的复杂关系,导致多跳推理任务中的响应不完整或不准确。
什么是 GraphRAG?
GraphRAG 通过在检索和生成过程中加入额外的知识图谱层来增强传统的 RAG 框架:
知识图谱集成:GraphRAG 不是检索简单的文本文档或段落,而是从知识图谱中检索包含有关实体及其关系的结构化信息的相关子图或路径。
情境化生成:LLM 使用检索到的图形数据来生成更准确、上下文丰富且逻辑连贯的响应。
GraphRAG 的关键组件:
知识图谱 (KG):
- 一个结构化数据库,以图形格式存储实体 (节点 ) 和关系 (边缘)。
- 包含丰富的语义信息和数据点之间的显式连接。
2.检索机制:
查询知识图谱以根据输入查找相关实体和关系。
利用图形遍历算法和查询语言,如 SPARQL 或 Cypher。
3.大型语言模型 (LLM):
接收输入查询以及检索到的图形数据。
生成由 KG 的输入和结构化知识告知的响应。
GraphRAG 是如何工作的?分步过程:
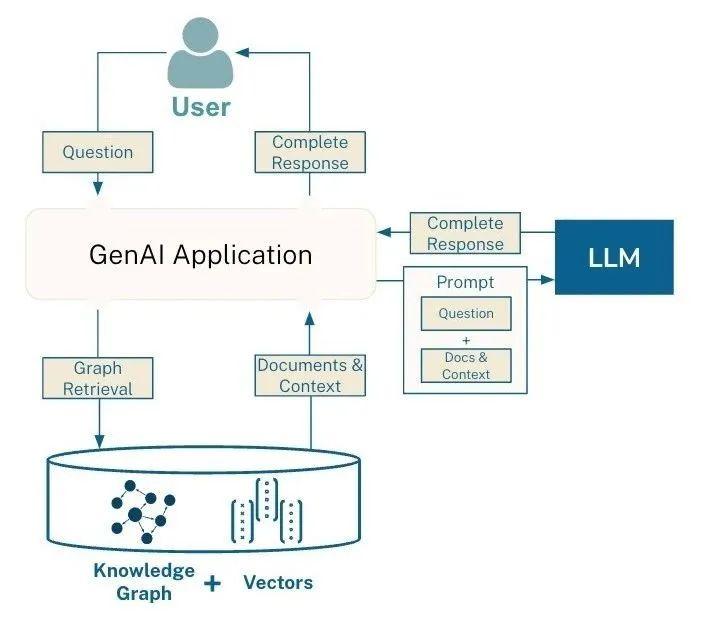
查询解释:
- 分析用户的输入查询以识别关键实体和意图。
- 自然语言理解 (NLU) 技术可用于解析查询。
** 图检索:**
- 根据解析后的查询,系统查询知识图谱以检索相关子图谱。
- 检索侧重于与查询相关的实体及其关系。
上下文嵌入:
- 检索到的图形数据将转换为 LLM 可以处理的格式。
- 这可能涉及线性化图形或将结构化数据嵌入到文本提示中。
响应生成:
- LLM 使用原始查询和知识图谱中的上下文信息生成响应。
- 生成的输出预计会更准确,幻觉的可能性也会降低。
后处理(可选):
- 可以根据知识图谱进一步优化或验证响应,以确保事实的正确性。
应用 2:AI 智能体之间的互作性
AI 智能体是一个自主实体,它观察其环境、做出决策并执行作以实现特定目标。这些代理的范围可以从执行预定义任务的简单程序到能够学习和适应的复杂系统。
多代理系统由在共享环境中交互的多个此类 AI 代理组成。在此设置中,代理可以协作、竞争或两者兼而有之,具体取决于系统的设计和目标。
Agent智能体互作性的重要性
代理互作性(不同代理相互理解并协同工作的能力)对于处理超出单个代理能力的复杂任务至关重要。在自动驾驶汽车、智能电网和大规模模拟等领域,没有一个代理可以有效地管理所有方面。 互作性确保代理能够:
- 高效沟通:无缝共享信息和意图。
- 协调行动:调整他们的行为以实现共同目标或避免冲突。
- 适应和学习:利用共享的经验随着时间的推移而改进。
如果没有互作性,代理可能会交叉工作,从而导致效率低下甚至系统故障。因此,建立一个用于理解和交互的通用框架对于多代理系统的成功至关重要。
知识图谱在智能体互作性中的作用
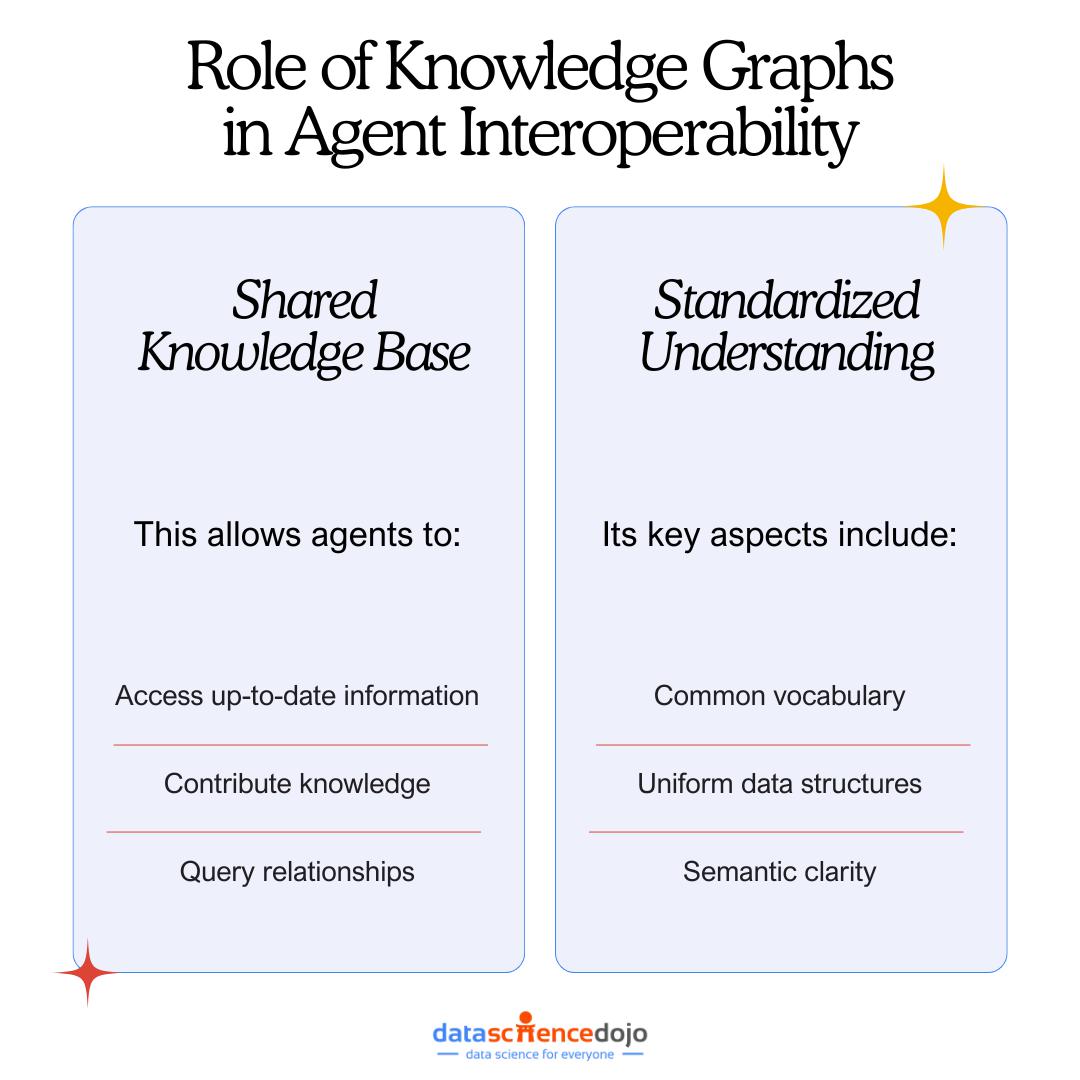
1.共享知识库
知识图谱 (KG) 充当结构化信息的集中存储库,系统内的所有代理都可以访问。通过将数据表示为相互关联的实体和关系,KG 提供了环境和代理本身的整体视图。这种共享知识库允许代理:
访问最新信息:检索有关环境、任务和其他代理的最新数据。
贡献知识:使用新发现或更改更新 KG,使系统的知识保持最新。
查询关系:了解不同实体如何连接,从而做出更明智的决策。
例如,在智慧城市场景中,交通管理代理、公共交通系统和紧急服务都可以访问包含有关道路状况、事件和资源可用性的实时数据的 KG。
2.标准化理解
知识图谱利用标准化的本体和架构来定义实体、属性和关系。这种标准化可确保所有代理都能一致地解释数据。关键方面包括:
- 常用词汇:代理使用相同的术语和定义,从而减少歧义。
- 统一的数据结构:用于表示信息的一致格式有助于解析和处理。
- 语义清晰:关系和实体类型的明确定义可增强理解。
通过遵守共享的本体,代理可以准确地解释彼此的消息和作。例如,如果一个代理引用 KG 中的“车辆”,则所有其他代理都了解该术语所包含的属性和功能。
使用知识图谱实现互作性的好处
1.高效沟通
借助知识图谱提供的共享本体,代理可以更有效地进行通信:
- 减少误解:通用定义可将误解的风险降至最低。
- 简化消息传递:代理可以直接引用实体和关系,避免冗长的解释。
- 清晰度更高:消息结构清晰且准确,有助于快速理解。
例如,在协调任务时,代理可以引用 KG 中的特定实体,其他代理可以立即了解上下文和相关详细信息。
2.协调行动
知识图谱通过提供以下功能,使座席能够更有效地协作:
- 系统状态的可见性:代理可以看到任务、资源和其他代理的当前状态。
- 冲突检测:了解其他代理的计划有助于避免重叠或干扰。
- 战略规划:代理可以将他们的行动与他人保持一致,以实现协同效应。
例如,在物流网络中,送货无人机(代理)可以使用 KG 来优化路线,避免拥堵,并通过相互协调确保及时交货。
3.可扩展性
使用知识图谱可以增强系统的扩展能力:
- 易于集成:新代理可以通过连接到 KG 并遵守已建立的本体来快速投入使用。
- 模块化:可以在不中断整个系统的情况下添加或删除代理。
- 灵活性:随着系统的发展,KG 可以不断发展以适应新型代理或数据。
这种可扩展性对于预期会随着时间的推移而扩展的系统至关重要,例如向交通网络添加更多自动驾驶汽车或将其他传感器集成到 IoT 生态系统中。
应用 3:个性化推荐系统
推荐系统概述
推荐系统是现代数字体验不可或缺的一部分,可推动个性化并提高用户参与度。它们帮助用户发现符合他们偏好的产品、服务或内容,使交互更加相关和愉快。
电子商务网站、流媒体服务和社交媒体等平台严重依赖这些系统来保持用户的参与度、提高满意度并促进持续互动。
传统方法 传统上,推荐系统使用两种主要技术:协作筛选和基于内容的方法。协作筛选依赖于用户与项目的交互(例如,用户评分或购买历史记录)来查找相似的用户或项目,并根据模式生成推荐。
另一方面,基于内容的方法使用项目的属性(例如,流派、关键字)将它们与用户偏好相匹配。虽然有效,但这些方法经常面临数据稀缺、缺乏上下文和对复杂用户需求的理解有限等问题。
使用知识图谱和 LLM 增强推荐
知识图谱集成
知识图谱通过以捕获用户、项目和上下文属性之间明确关系的方式构建数据来增强推荐系统。
通过集成 KG,该系统丰富了数据集,超越了简单的用户与项目交互,使其能够存储有关实体的详细信息,例如产品类别、流派、评级和用户偏好,以及它们的相互联系。
例如,KG 可能会将用户个人资料与他们最喜欢的类型、首选价格范围和以前购买的商品联系起来,从而构建一个包含兴趣和行为的综合地图。
用于个性化的 LLM
大型语言模型 (LLM) 为这些丰富的数据集带来了动态的个性化层。它们利用 KG 数据来了解用户的偏好和上下文,以自然语言生成高度定制的推荐。
例如,LLM 可以分析 KG 以查找超出基本属性的联系,例如确定喜欢“科幻小说”的用户也可能喜欢有关太空探索的纪录片。然后,LLM 将这些见解阐明为感觉个性化和直观的建议,通过对话式、上下文感知建议增强用户体验。
与传统方法相比的优势
1.更深入的洞察
通过利用 KG 的互连结构,LLM 驱动的系统可以发现传统方法可能会遗漏的不明显的关系。例如,如果用户经常浏览烹饪节目和健身应用程序,系统可能会推荐健康博客或健康食谱书,通过微妙的多跳推理将点点滴滴联系起来。 此功能增强了对新内容的发现,丰富了用户体验,而不仅仅是简单的项目相似性。
2.情境感知建议
LLM 与 KG 结合使用时,可提供符合用户当前情况或意图的上下文感知推荐。例如,如果系统检测到用户在深夜搜索用餐选项,它可以优先考虑附近仍在营业的餐厅,以满足用户的即时需求。 这种整合实时数据(如位置或时间)的能力可确保推荐既相关又及时,从而提高系统的整体实用性。
3.提高多样性
传统方法的关键限制之一是“过滤气泡”,即用户被反复显示相似类型的内容,从而限制了他们获得新体验的机会。KG 和 LLM 在提出推荐时通过考虑更广泛的属性和关系来打破这种模式。 这意味着用户可以接触到多样化但相关的选项,例如向他们介绍他们尚未探索但符合他们兴趣的类型。这种方法不仅可以提高用户满意度,还可以提高系统的能力,以新鲜、引人入胜的内容给用户带来惊喜和愉悦。
利用知识图谱实现 AI 转型
知识图谱 (KG) 与大型语言模型 (LLM) 的集成标志着 AI 技术的变革性转变。虽然像 GPT-4 这样的 LLM 在生成类似人类的文本方面表现出了卓越的能力,但它们在解决幻觉和缺乏深入的上下文理解等问题方面却在努力。
KG 提供了一种结构化、互连的方式来存储和检索信息,为 LLM 的准确性和一致性提供了必要的基础。通过利用 KG,基于图形的检索增强生成 (RAG)、多代理互作性和推荐系统等应用程序正在演变为更复杂的上下文感知解决方案。这些系统现在受益于以前无法实现的深入洞察、高效通信和多样化、个性化推荐。
随着 AI 领域的不断扩大,知识图谱和 LLM 之间的协同作用将至关重要。这种强大的组合解决了 LLM 的局限性,为 AI 应用程序开辟了新的途径,这些应用程序不仅准确,而且与真实世界数据的复杂性和细微差别深度一致。
知识图谱不仅仅是一种工具,还是构建下一代智能、可靠的 AI 系统的基础。



